


Summary
2020.07.13 ~ 2020.08.29 까지 진행한 Naver AI Rush에 관련된 후기
Naver AI Rush
AI Rush는 네이버에서 진행하는 대회이다.
주어진 문제에 대한 가장 점수가 높은 인공지능 모델을 개발하는 대회이다.
대회 지원
6월쯤에 친구로부터 대회를 알게 되고 거의 마지막 날에 지원하게 되었다.
지원할 때 지원서를 적게 되는데 대충 학력, 지원 동기, 1라운드 때 원하는 주제, 다른 AI 관련 경험 등을 적는다.
1라운드
1라운드는 총 100명이 선정되어 진행했는데 7/13 ~ 7/31 정도까지였던 걸로 기억한다.
올해는 1라운드 주제가 이미지 분류, 혐오 댓글 분류 2개였는데 주제별 상위 25명 즉, 상위 50명이 2라운드로 진출하게 된다.
1라운드 진행
올해만 그런지는 모르겠으나 코로나로 인해 온라인으로 진행되었다.
정해진 시간에 회의에 참석하거나 그런 건 없고 그냥 점수만 올리면 된다.
1라운드 때 나는 혐오 댓글 분류를 진행했다.
1라운드 결과
결과는 혐오 댓글 분류 13등 총 순위 26등으로 끝이 났다.
Baseline 코드는 네이버에서 주어지고 여기서 모델과 전처리 등만 진행하면 된다.
Baseline 코드는 Pytorch로 짜여진 코드가 주어졌다.
물론 본인이 원하면 코드를 처음부터 짜서 제출해도 되지만, 개인적으로는 별로 추천하지 않는다.
왜냐하면, NSML이라는 환경을 사용하게 되는데 이 환경에서 학습하고 결과를 제출하기 위해서는 어떤 코드를 조금 추가해야 한다.
2라운드
2라운드는 1라운드 상위 50명이 진행했는데 8/3 ~ 8/26까지 진행했다.
2라운드는 주제가 8개 정도 되었는데 올해는 아래와 같은 주제들이 있었다.
- 글의 분위기, 톤, 문법을 종합 평가/추천 (Grammary)
- 리뷰 이미지의 자동 분류
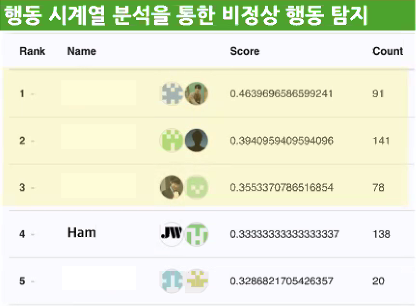
- 이용자 행동의 시계열 분석을 통한 비정상적인 행위 탐지
- 음원 및 메타 정보 이용하여 스테이션 분류
- 음원 및 메타 이용 무드 태그 분류
- 음원 및 메타 이용 일본 장르 분류
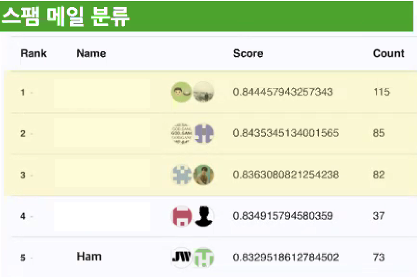
- 스팸 메일 분류
- 화자 분류
이 중 나와 팀원은 이상치 탐지, 스팸 메일 분류, 무드 태그 분류 3개를 진행했다.
2라운드 진행
2라운드부터는 정말 대회가 본격적으로 진행되는 것 같았다.
2라운드부터는 사원증도 본인 것으로 발급되고 네이버에 직접 출근하면서 회의실에 대회 참가자들이 모두 모여 개발을 했다.
팀 빌딩
2라운드는 2인 1조로 진행하게 되는데 올해 조 편성은 두 가지 방법으로 진행되었다.
- 팀 빌딩 때 팀을 구해 팀 생성
- 1가지 주제를 정하고 같은 주제를 정한 사람들끼리 제비뽑기를 하여 같은 숫자를 뽑은 사람과 팀 생성
나는 스팸 메일 분류를 선택했고 같은 주제를 선택한 팀원과 팀을 이뤘다.
주제 선정
주제 선정도 1라운드와 차이가 있었는데 주제를 1가지만 진행하는 것이 아니다.
우선 팀이 선택한 주제 1~2개 + 대회 측에서 배정한 주제 1개 해서 최소 2개에서 3개를 진행해야 한다.
이 중 우리 팀은 스팸 메일 분류, 이상치 탐지를 선택했고 무드 태그 분류를 배정받았다.
2라운드 결과
우리 팀은 대회 측에서 배정받은 주제까지는 신경 쓰지 못할 것 같아서 이상치 탐지와 스팸 메일 분류에 집중했다.
나는 스팸 메일 분류를 맡았고 팀원은 이상치 탐지를 맡았다.
결과는 이상치 탐지 4등, 스팸 메일 분류 5등을 해서 되게 아쉬웠다.
후기
1라운드 후기
1라운드 때는 개인전으로 진행되었는데 인공지능을 이번 기회에 처음 하다 보니까 조금 어려웠고 헤맸다.
데이터를 보면서 공부를 하고 싶었는데 개인정보보호 때문에 숫자로 tokenizing된 정보를 주어서 많이 헤맸었다.
이때는 무엇을 먼저 건드려야 할지, 이 코드가 무엇을 의미하는지 convolution, dropout 등이 무엇을 의미하는지 파악하는 데에 시간을 많이 써서 아쉬웠던 것 같다.
2라운드 후기
우선 2라운드에서 놀란 점은 이 대회에 대학원생분들 및 AI를 공부 및 연구하시는 분들이 되게 많이 지원했다는 것이다.
그래서 이 대회에 있어서 좀 더 진지하고 열정적으로 저 분들을 뛰어넘어 봐야지 라는 생각이 들어 자극이 많이 되었다.
좋았던 점은 2라운드 때는 팀전으로 진행되어 팀원과 알게 된 정보를 공유하며 하는 게 되게 좋았다.
내가 검색하거나 논문을 통해 알게 된 정보를 공유할 수 있고 상대방 측도 그런 정보들을 공유해서 서로 발전해 나갈 수 있었다.
2라운드 때는 데이터를 분석해보니 노이즈, 중복된 데이터들이 많아서 데이터 전처리가 핵심일 것으로 생각했었다.
그래서 데이터 전처리에 거의 1~2주를 사용했는데 별 효과가 없었던 것이 아쉬웠다.
단, 2라운드도 개인정보보호 때문에 숫자로 tokenizing 된 데이터들이 주어졌다.
마지막 3일 전날에 모델 설계에 감이 잡혀서 9등에서 점수를 많이 올렸지만, 최종적으로 5등을 한 것이 매우 아쉬웠다.
전체 후기
나는 기존에 인공지능을 공부해본 적이 없어 이번에 대회를 통해 인공지능을 공부해보자는 생각으로 지원하게 되었다.
그런데 지원서에 AI 관련 경험도 칸을 비우고 제출했었고 코딩테스트를 매우 못 봐서 당연히 떨어졌겠지 하고 있었는데 아르바이트하는 도중에 합격했다는 문자가 와서 당황했다.
그래서 7월은 아르바이트를 하면서 1라운드 진행을 하여 정말 힘든 한 달이었다.
그래도 8월 한달 동안은 네이버라는 기업에 다니면서 분위기, 복지 등을 알 수 있어서 즐거웠고
모두의 딥러닝 강의를 제작하신 김성훈 교수님을 직접 뵐 수 있어서 정말 영광이었다.
또한, 네이버 실무 PM분들과 만남을 가질 수 있는 기회도 정말 좋았다.
단, 코로나로 인해 중간에 모두 재택근무로 바뀐 점이 조금 아쉬웠다.
이번 대회를 진행하면서 인공지능에 대해 공부하고 여러 논문들에 나온 기법들을 적용해보는 것이 재밌었다.
정말 재미있는 한달 이였고 내년에도 기회가 된다면 이 대회에 다시 참가할 의향이 있고 그땐 지금보다 더 성장해서 입상을 해보고 싶다.
NSML
NSML이라는 머신러닝 학습을 위한 AWS같은 서버를 제공해주는데 돌아보니 정말 좋은 기회였던 것 같다.
대회가 끝나고 인공지능을 좀 더 공부하려고 하니 본인의 컴퓨터, colab이나 AWS같은 유료 서비스를 이용해야 해서 불편함이 느껴졌다.
막상 대회를 진행하는 동안에는 이런 자원을 제공해주다 보니 모델에 여러가지를 적용시키고 학습시키는 데 불편함이 없었다.
챌린지 수행비 및 대회 상금
대회인데 돈을 정말 많이 주는 것 같다.
놀란 것이 2라운드 때 우승한 팀들만 상금을 주는 줄 알았는데 1라운드 참여비 + 1라운드 성과비, 2라운드 참여비 + 2라운드 상금이라고 생각하면 된다.
2라운드 진출만 하면 300 이상은 받는다.
또한, 2라운드 상금이 모든 모델을 합하여 1, 2, 3등을 뽑는 줄 알았는데 각 주제별 1, 2, 3 등에 각각 1500, 700, 300씩 주는 거였다.
거기다가 입상하면 네이버 관련 직군 지원 시 면접기회를 바로 받으니 정말 좋은 대회인 것 같다.
데이터
이번에 대회를 진행할 때 데이터를 보면서 여러 가지 전처리 들을 해보고 싶었는데 개인정보보호 때문에 숫자로 된 정보만을 받아 조금 아쉬웠던 것 같다.
데이터가 보이지 않으니 대회가 자연스럽게 모델 설계 중심으로 진행되었던 것 같다.
팁
-
AI와 관련된 활동이 없는데도 붙은 걸 봐서 아마 성장 가능성이나 노력하는 모습도 보는 것 같다.
만약 AI와 관련된 활동이 없어서 지원을 꺼리고 있다면 우선 지원해 보는 것이 좋을 것 같다. -
내년에도 그럴지 모르겠자만 만약 숫자로된 데이터를 준다면 데이터 전처리 보다는 모델 설계에 중심을 두는게 좋을 것 같다.
-
PM분들을 만나서 해당 분야로 가고 싶은 사람은 진로를 여쭤봐도 좋고 대회 문제에 대해 여쭤보는 것이 많은 도움이 될 것이다.
